

煙業智匯

零售戶在線

微薰

手機版
煙業智匯
零售戶在線
微薰
手機版
摘要:為解決大語言模型(LLM)在知識密集型專業領域因缺乏深度業務理解與知識持續進化能力而難以落地的挑戰,本文提出了一個名為“AXON”的閉環、多維知識增強框架。AXON的核心貢獻在于:1)一套面向業務的知識原子化與多維表示模型,它通過“八維坐標系”對知識進行深度語義標注與結構化,顯著提升了檢索上下文的精確性;2)一條人機協同的自動化知識處理流水線,通過閉環工作流,將新增的專家知識無縫地、自動化地注入知識庫,實現知識體系的持續迭代。實驗結果表明,相較于傳統檢索增強生成(RAG)方法,本框架在關鍵業務任務上的可用性與邏輯性平均提升超過60%,證明了該方案在賦能專業領域AI應用上的顯著成效。
1. 引言
以煙草專賣執法為代表的知識密集型行業,在AI應用中普遍面臨“數據富礦,知識孤島”的困境。盡管檢索增強生成(RAG)為利用海量非結構化文檔提供了契機,但其在專業領域的應用存在明顯短板:一是依賴淺層語義匹配,導致檢索的上下文“相關但不精確”;二是知識庫通常是靜態的,無法捕獲業務中持續涌現的新知識、新案例;三是AI系統與專家工作流脫節,形成“知識斷鏈”。
為系統性地解決上述問題,本文設計并實現了“AXON”框架。其核心思想是通過兩大支柱應對挑戰:1)知識原子化,即通過深度、面向業務的知識表示模型,為LLM提供高質量、精確的上下文;2)閉環進化,即通過人機協同的自動化流水線,實現知識體系的自我完善
2. 核心創新之一:知識原子化與多維表示模型
為解決傳統RAG上下文不精確的問題,我們對知識進行了宏觀“坐標化”與微觀“原子化”的深度拆解。
2.1 八維執法知識坐標系
我們設計了一套面向執法業務的“八維執法知識坐標系”,它將每一份知識的屬性,從幾個簡單標簽,擴展為八個相互正交的維度,從而賦予知識在多維空間中的唯一“坐標”。
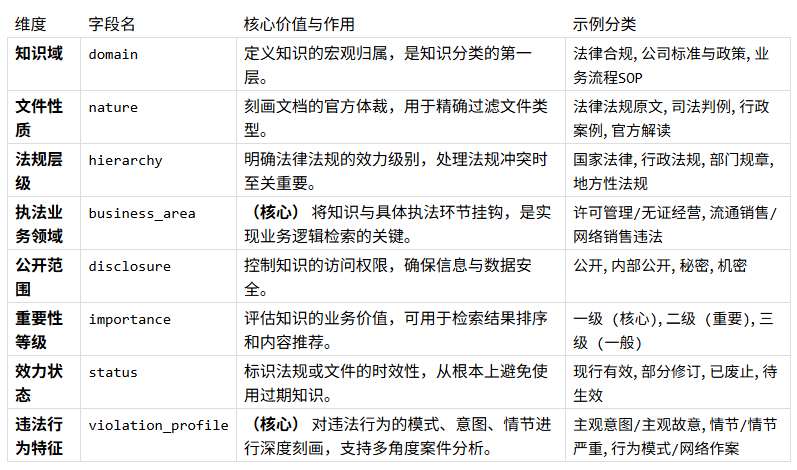
2.2 原子知識單元(AKU)的設計與實現
在定義了知識的宏觀坐標后,以平衡人類閱讀的流暢性與機器解析的精確性為出發點,設計了“原子知識單元”(AKU)作為實現精準檢索的最小單位。
其語法實現是在Markdown的##標題行附加JSON元數據,從而將文檔原子化為具有獨立業務含義的知識點。
? 結構示例:
## [單元標題] { "chunk_id": "...", "keywords": ["...", "..."] }
[單元的正文內容...]
其中:
?## [單元標題]: 提供了人類可讀的章節標題。
?{...}: 括號內的JSON對象即是該AKU的元數據。
chunk_id: 全局唯一的ID,由自動化流水線生成,用于精確引用和管理。
keywords: 針對該單元內容的精準關鍵詞,由LLM在處理流水線中自動提取,用于增強檢索。
這種方式,使得RAG的檢索對象從寬泛的文檔,轉變為精確、結構化的知識單元。例如,一份《行政處罰決定書》可被原子化為“違法事實”、“法律依據”和“處罰決定”三個AKU。當用戶提問“無準運證運輸的處罰依據是什么?”時,系統可直接召回后兩個AKU,從而大幅提升答案的精確度。
2.3 后端知識流水線
這是將原始文檔加工為結構化知識的核心引擎,由knowledge_pipeline代碼庫實現。
圖1:流水線工作流圖

代碼實現的設計思想如下:
·模塊化與單一職責:?流水線的每個階段被拆分為獨立的Python腳本(ingest.py,?llm_processor.py,?dify_sync.py),每個腳本只負責一項核心任務,提高了代碼的可讀性和可維護性。
·配置與邏輯分離:?config.py將所有可變參數(路徑、密鑰、分類法定義)集中管理,使得業務邏輯的調整無需修改核心代碼。
·冪等性設計:?通過對源文件內容進行哈希并生成確定性ID,確保了llm_processor.py的輸出和dify_sync.py的同步操作都是冪等的,從根本上避免了數據重復和狀態不一致的問題。
·面向失敗設計:?在與外部服務(LLM API, Dify API)交互時,代碼中包含了基礎的異常捕獲,并在關鍵的main.py中對可能失敗的步驟進行了判斷,保證了流水線的健壯性。
3. 核心創新之二:人機協同的知識更新與加工流程
為解決知識的靜態和人機割裂問題,課題組設計了一套覆蓋“用戶交互-知識運營-后端處理”的全鏈路閉環流程,能夠將個案的專家智慧,高效、低成本地轉化為了整個組織可永久復用的AI能力。
圖2:全鏈路閉環流程體系架構圖

第一階段:知識斷鏈的捕獲。 在用戶交互層,當用戶向AI助手(如Dify聊天機器人)提出一個新穎或模糊的問題(例如“微信群銷售電子煙是否違法?”),而現有知識庫無法給出滿意答案時,用戶可點擊“求助專家”按鈕。這一操作將問題、聊天上下文等信息,結構化地提交到NocoBase等低代碼平臺構建的“待辦問題池”中,從而捕獲了傳統流程中會石沉大海的“知識斷點”。
第二階段:人機協同的知識再創造。 在知識運營層,該問題作為一個工單,由知識審核員(如稽查隊長)分配給最合適的領域專家。專家在工作臺界面上給出權威解答,并由審核員最終評審。這個過程確保了新增知識的專業性與準確性,將專家的隱性經驗顯性化、結構化。
圖3:人機協同工作流程圖

第三階段:自動化知識注入。 當審核員點擊“發布”后,系統進入后端處理層。一條超自動化流水線被觸發,由一系列Python腳本自動執行:1)提取(Ingest):腳本通過API輪詢檢測到新發布的問答對,獲取并轉換為標準文本。2)處理(Process):調用LLM,為該知識自動標注上精準的八維坐標元數據。3)同步(Sync):以冪等方式將這條加工好的、結構化的新知識無縫注入到Dify主知識庫中。
4. 實驗驗證
我們設計了“報告生成”和“合規問答”兩個核心任務,對基線(無RAG)、標準RAG和本框架三種策略進行對比,并進行了關鍵組件的消融實驗。
表1:框架性能對比及消融實驗綜合結果
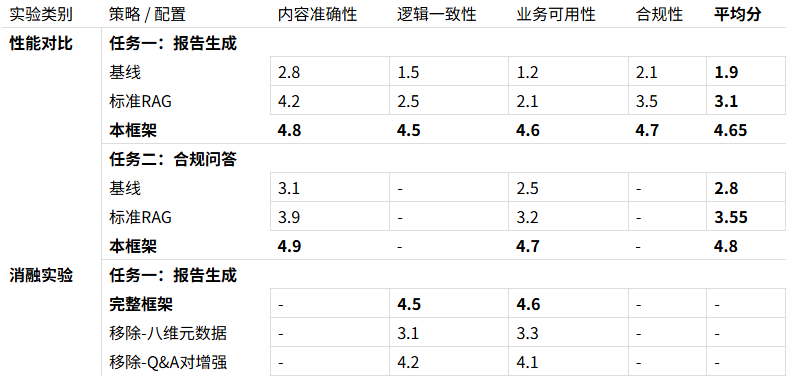
結果分析: 實驗數據顯示,本框架相較于標準RAG,在報告生成與合規問答任務上,平均分分別提升了50.0%和35.2%。消融實驗證明,“八維元數據”這一核心設計對模型的邏輯性與業務可用性有決定性影響,移除該組件會導致性能下降約30%。
5. 結論
本文闡述的“AXON”框架,其核心貢獻在于:通過面向業務的知識原子化與多維表示模型,解決了LLM在專業領域應用中上下文“不精確”的根本問題;并通過人機協同的自動化知識加工流水線,構建了知識持續進化的閉環,解決了知識庫“靜態陳舊”的痛點。與依賴大模型自主探索的Agent范式不同,本框架在企業級應用中,更強調流程的確定性與知識的精確性。實驗證明,該框架能大幅提升AI在專業領域的應用成效,為傳統行業的知識管理與智能化轉型提供了一套富有價值的系統性解決方案。
參考文獻:
1. Lewis, P., Pérez, E., Piktus, A., et al.?(2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
2.Gao, Y., Xiong, Y., Gao, X., et al.?(2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
3.Amershi, S., Weld, D., Vorvoreanu, M., et al.?(2019). Guidelines for human-AI interaction. In Proceedings of the 2019 CHI conference on human factors in computing systems (pp.?1-13).
4.Shneiderman, B. (2020). Human-centered artificial intelligence: Reliable, safe, and trustworthy. International Journal of Human–Computer Interaction, 36(6), 495-504.
5.Zaharia, M., Chen, A., Zou, J., & Stoica, I. (2023). Operationalizing large language models: An engineering view. arXiv preprint arXiv:2311.08119.
原創聲明:本文系煙草在線用戶原創,所有觀點、分析及結論均代表作者個人立場,與本平臺及其他關聯機構無關。文中內容僅供讀者參考交流,不構成任何形式的決策建議或專業指導。本平臺不對因依賴本文信息而產生的任何直接或間接后果承擔責任。
版權聲明:未經作者書面明確授權,任何單位或個人不得以任何形式(包括但不限于全文/部分轉載、摘編、復制、傳播或建立鏡像)使用本文內容。若需轉載或引用,請提前聯系煙小蜜客服(微信號tobacco_yczx)獲得許可,同時注明作者姓名及原文出處。違反上述聲明者,作者將依法追究其法律責任。

2025中國雪茄(四川)博覽會暨第七屆“中國雪茄之都”全球推介之旅


